One of the pitched battles in this century’s cyber war is about advert blocking and injecting.
It’s in full flow.
You can tell – journalist friends complaining that ad blockers have killed Joystiq, a 10 year old gaming magazine; web friends complaining that an ad blocker charges advertisers to not block some ads.
I’ve got some perspective.
Back in 1996, I helped make one of the earliest web advert blockers, WebMask.
Why did we do it?
The early web was fundamentally non-commercial. It was built so as not to be CompuServe or The Microsoft Network. I often bought copies of Adbusters magazine, which unpicked how runaway consumerism harms our culture and our health.

Our advert blocker was a side project which quickly died. Fascinated with the different technologies that could be used to block ads, for years I maintained the most popular page listing such software.
A little later, I used the traffic from that to give instructions on removing all manner of commercial internet material.
The adverts inside web sites animate, flash and distract. Wouldn’t it be nice to get rid of them? They are not unethical like the other nasties on this page. Indeed, some consider it stealing from the site’s ad revenue to block them. Others either don’t believe in the need for such self sacrifice, object to adverts in principle, or say that since they never click on them anyway no revenue is lost. You decide.
A telling quote.
What’s happening now?
Everyone wants to control our adverts.
Google intercepts our very quest for information to take a sneaky cut – a tax – on everything that we buy online. Facebook uses our addiction as social primates to relationships to sell us corporate brands.
Content creators embed multiple tracking devices, sending our most personal information to complex morasses of robot hucksters.
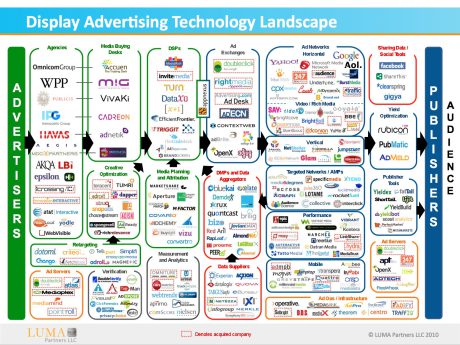
When the industry finds that people didn’t look at or click the distracting ads any more, they instead place adverts which look like camouflaged tabloid stories.
Or sod it all, just publish fake stories that are actually adverts. After all, what’s it matter, if all the real stories are just retyped PR churnalism?
Real time exchanges auction the pixels on our screen based on our profile, to sell us things we had tried to decide we couldn’t afford to buy. Or just to remind us that we think we’re fat.
My mother rang up the other day asking “what this Bing thing is”. She didn’t like it, not as good as Google. The routine update of some standard software had changed her default search engine. Despite being an experienced user of computers, she had no idea how to change it back.
I can’t even blame this on malware – her web browser’s maker does much the same thing.
Even the hardware manufacturers are at it – Leonovo using their power over our metal to inject new adverts into web pages (risking the security of online banking and shopping in the process).
Such a battle.
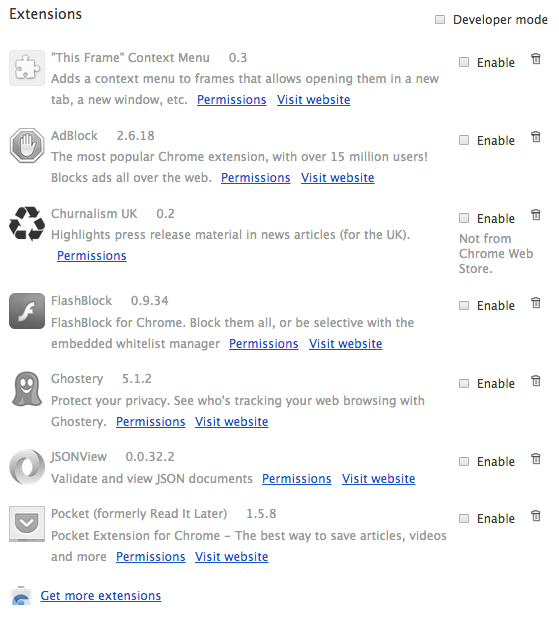
What’s the complaint about AdBlock?
As of September there were 144 million active AdBlock users.
It’s no longer a geek thing, like it was when I first blocked ads back in 1996. It’s upsetting some content creators.
In my view, the complaint here is that the users are finally trying to control their adverts. How dare they!
Sorry, but everyone else is trying to control our brains (you saw my list in the section above). Why shouldn’t we try to control them too?
This is a long cold cyberwar. As such it is “zero sum” – nobody is going to do well out of this. To expect me to act morally on behalf of the other combatants during a war has chutzpah, and is a futile expectation.
I’m not going to let advertising companies win the control of our information society by doing whatever they say as if that were morally pure.
Maybe if they had a good business model that helped me out. But they don’t.
Advert companies and advert-funded companies aggregate our private information without our knowing permission. They create insecure data vaults and comms channels, which then governments and criminals easily dip into. They secretly run psychological experiments on our social lives.
If you are going to do whatever you like on your general purpose computer (a server), then I’m going to do whatever I like on my general purpose computer (my laptop). Tough luck.
We can have a truce, but you need to parley first. All sides have to give things up.
Of course it is not that simple. Who controls the power of general purpose computation is one of the key hard challenges of our generation.
We’re not going to solve it in five minutes having a chat on social media. It requires the great casualities, then the concerted dipomacy that led to, say, the Geneva Protocol, which banned chemical weapons.
And even then… Well, physical war hasn’t ended, has it.
Who is coming to harm in this war?
I spent a long time angsting about investigative journalism – how can it get funded on the Internet?
Digging into the world in detail is vital to society. I’ve tried to help by helping journalists use data – we have many journalist users at ScraperWiki to this day.
Adverts are not the answer – the kind of journalism I want doesn’t drive traffic. Take a look at the celeb soft porn of the (profitable) Mail Online front page. It’s very different from the newstand Daily Mail’s crazed politics front page. Telling as to what kind of journalism Internet advertising funds.
In my view philanthropy is the best business model we’ve got for good, socially worthwhile journalism. Look at the excellent ProPublica for an example.
[ Aside: Perhaps it always was the model – a long time ago in US cities, newspapers got their money from classified ads. They didn’t need to do socially useful exposés of corruption to keep that money, but their owners chose to anyway. They loved their city. ]
The other main victim is the smaller content creators. You can feel their pain in Matthew Hughes’s article about AdBlock on MakeUseOf.
If you use AdBlock, know you are still screwing over hard working people, because you can’t be bothered to be mildly inconvenienced. (Tweet)
I don’t have a great prescription for them. Use technologies that block advert blockers – preferably inviting your readers to unblock your site, or donate instead. Make sure your advertiser is one of the ones that pays AdBlocker (see below). Only show quality adverts. Try (again!) other business models.
My larger scale prescription for creators is – create standards! Have a proper RFC for a protocol for adverts, and get a standard system for distributed payment built into all browsers (BitCoin’s children will get there in the end).
These will reduce the costs, make the relationship more directly between producer and consumer, and get rid of the parasitical, big data optimising tech advert industry.
Forming the protocols would be a good peace conference.
Conclusion
AdBlocker, in its form which exhorts advertisers to pay it to let their adverts through, is providing value. It is improving the quality of adverts with its acceptable ads criteria. Adverts shouldn’t obscure content, they shouldn’t fill up most of the page, they should be clearly marked.
I don’t think that’s blackmail – on the contrary, I think it is a fascinating step towards the terms which should be in the final truce.
Meanwhile though, some users either doubt that AdBlock itself hasn’t been corrupted by money, or want to carry on in pitched battle. They’ve moved on to forks of it that continue to block all adverts.
Others are more adventurous.
Brett Lempereur, following an argument in the pub in Liverpool, made Sadblock. It is a morally sound ad blocker. When it detects the adverts, it blocks the entire page – so you can no longer be accused of stealing the content.
If you don’t find even that kind enough to article writers, there’s one final ad blocking option. AdNauseum is a funky AdBlock expansion which loads all the adverts invisibly, and quietly fakes that you clicked on them.
Bliss – no adverts, and money goes to the journalists. (Something not quite right here – who’s losing out again?)
Of course, all that is just users taking control.
The ultimate control?
Moving on from it to form a new technology industry, with better business models, and a better heart.
P.S. The collapse of Joystiq which started this recent argument about advert blocking has a final twist. It has been resurrected as part of Engadget.









{kind=link}
{kind=link}
{kind=link}
{kind=link}